Measures of Variation
Learning Outcomes
- Calculate the mean, median, and mode of a set of data
- Calculate the range of a data set, and recognize it's limitations in fully describing the behavior of a data set
- Calculate the standard deviation for a data set, and determine it's units
- Identify the difference between population variance and sample variance
- Identify the quartiles for a data set, and the calculations used to define them
- Identify the parts of a five number summary for a set of data, and create a box plot using it
Range and Standard Deviation
Consider these three sets of quiz scores:Section A: 5 5 5 5 5 5 5 5 5 5
Section B: 0 0 0 0 0 10 10 10 10 10
Section C: 4 4 4 5 5 5 5 6 6 6
All three of these sets of data have a mean of 5 and median of 5, yet the sets of scores are clearly quite different. In section A, everyone had the same score; in section B half the class got no points and the other half got a perfect score, assuming this was a 10-point quiz. Section C was not as consistent as section A, but not as widely varied as section B. In addition to the mean and median, which are measures of the "typical" or "middle" value, we also need a measure of how "spread out" or varied each data set is. There are several ways to measure this "spread" of the data. The first is the simplest and is called the range.
There are several ways to measure this "spread" of the data. The first is the simplest and is called the range.
Range
The range is the difference between the maximum value and the minimum value of the data set.example
Using the quiz scores from above, For section A, the range is 0 since both maximum and minimum are 5 and 5 – 5 = 0 For section B, the range is 10 since 10 – 0 = 10 For section C, the range is 2 since 6 – 4 = 2 In the last example, the range seems to be revealing how spread out the data is. However, suppose we add a fourth section, Section D, with scores 0 5 5 5 5 5 5 5 5 10. This section also has a mean and median of 5. The range is 10, yet this data set is quite different than Section B. To better illuminate the differences, we’ll have to turn to more sophisticated measures of variation. The range of this example is explained in the following video. https://youtu.be/b3ofWalrHgQStandard deviation
The standard deviation is a measure of variation based on measuring how far each data value deviates, or is different, from the mean. A few important characteristics:- Standard deviation is always positive. Standard deviation will be zero if all the data values are equal, and will get larger as the data spreads out.
- Standard deviation has the same units as the original data.
- Standard deviation, like the mean, can be highly influenced by outliers.
| data value | deviation: data value - mean |
|---|---|
| 0 | 0-5 = -5 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 5 | 5-5 = 0 |
| 10 | 10-5 = 5 |
| data value | deviation: data value - mean | deviation squared |
|---|---|---|
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 5 | 5-5 = 0 | 02 = 0 |
| 10 | 10-5 = 5 | (5)2 = 25 |
[latex]\begin{align}&\text{populationstandarddeviation}=\sqrt{\frac{50}{10}}=\sqrt{5}\approx2.2\\&\text{or}\\&\text{samplestandarddeviation}=\sqrt{\frac{50}{9}}\approx2.4\\\end{align}[/latex]
If we are unsure whether the data set is a sample or a population, we will usually assume it is a sample, and we will round answers to one more decimal place than the original data, as we have done above.To compute standard deviation
- Find the deviation of each data from the mean. In other words, subtract the mean from the data value.
- Square each deviation.
- Add the squared deviations.
- Divide by n, the number of data values, if the data represents a whole population; divide by n – 1 if the data is from a sample.
- Compute the square root of the result.
example
Computing the standard deviation for Section B above, we first calculate that the mean is 5. Using a table can help keep track of your computations for the standard deviation:| data value | deviation: data value - mean | deviation squared |
|---|---|---|
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 0 | 0-5 = -5 | (-5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
| 10 | 10-5 = 5 | (5)2 = 25 |
[latex]\sqrt{\frac{25+25+25+25+25+25+25+25+25+25}{10}}=\sqrt{\frac{250}{10}}=5[/latex]
Notice that the standard deviation of this data set is much larger than that of section D since the data in this set is more spread out. For comparison, the standard deviations of all four sections are:| Section A: 5 5 5 5 5 5 5 5 5 5 | Standard deviation: 0 |
| Section B: 0 0 0 0 0 10 10 10 10 10 | Standard deviation: 5 |
| Section C: 4 4 4 5 5 5 5 6 6 6 | Standard deviation: 0.8 |
| Section D: 0 5 5 5 5 5 5 5 5 10 | Standard deviation: 2.2 |
Try It
The price of a jar of peanut butter at 5 stores was $3.29, $3.59, $3.79, $3.75, and $3.99. Find the standard deviation of the prices.Quartiles
Quartiles are values that divide the data in quarters. The first quartile (Q1) is the value so that 25% of the data values are below it; the third quartile (Q3) is the value so that 75% of the data values are below it. You may have guessed that the second quartile is the same as the median, since the median is the value so that 50% of the data values are below it. This divides the data into quarters; 25% of the data is between the minimum and Q1, 25% is between Q1 and the median, 25% is between the median and Q3, and 25% is between Q3 and the maximum value.Five number summary
The five number summary takes this form:Minimum, Q1, Median, Q3, Maximum
To find the first quartile, Q1
- Begin by ordering the data from smallest to largest
- Compute the locator: L = 0.25n
- If L is a decimal value:
- Round up to L+
- Use the data value in the L+th position
- If L is a whole number:
- Find the mean of the data values in the Lth and L+1th positions.
To find the third quartile, Q3
Use the same procedure as for Q1, but with locator: L = 0.75n Examples should help make this clearer.examples
Suppose we have measured 9 females, and their heights (in inches) sorted from smallest to largest are: 59 60 62 64 66 67 69 70 72 What are the first and third quartiles?Answer: To find the first quartile we first compute the locator: 25% of 9 is L = 0.25(9) = 2.25. Since this value is not a whole number, we round up to 3. The first quartile will be the third data value: 62 inches. To find the third quartile, we again compute the locator: 75% of 9 is 0.75(9) = 6.75. Since this value is not a whole number, we round up to 7. The third quartile will be the seventh data value: 69 inches.
Suppose we had measured 8 females, and their heights (in inches) sorted from smallest to largest are: 59 60 62 64 66 67 69 70 What are the first and third quartiles? What is the 5 number summary?
Answer: To find the first quartile we first compute the locator: 25% of 8 is L = 0.25(8) = 2. Since this value is a whole number, we will find the mean of the 2nd and 3rd data values: (60+62)/2 = 61, so the first quartile is 61 inches. The third quartile is computed similarly, using 75% instead of 25%. L = 0.75(8) = 6. This is a whole number, so we will find the mean of the 6th and 7th data values: (67+69)/2 = 68, so Q3 is 68. Note that the median could be computed the same way, using 50%.
The 5-number summary combines the first and third quartile with the minimum, median, and maximum values. What are the 5-number summaries for each of the previous 2 examples?
Answer: For the 9 female sample, the median is 66, the minimum is 59, and the maximum is 72. The 5 number summary is: 59, 62, 66, 69, 72. For the 8 female sample, the median is 65, the minimum is 59, and the maximum is 70, so the 5 number summary would be: 59, 61, 65, 68, 70.
More about each set of women's heights is in the following videos. https://youtu.be/00iQvPOOUu4 https://youtu.be/x73G2Nep05gReturning to our quiz score data: in each case, the first quartile locator is 0.25(10) = 2.5, so the first quartile will be the 3rd data value, and the third quartile will be the 8th data value. Creating the five-number summaries:
| Section and data | 5-number summary |
| Section A: 5 5 5 5 5 5 5 5 5 5 | 5, 5, 5, 5, 5 |
| Section B: 0 0 0 0 0 10 10 10 10 10 | 0, 0, 5, 10, 10 |
| Section C: 4 4 4 5 5 5 5 6 6 6 | 4, 4, 5, 6, 6 |
| Section D: 0 5 5 5 5 5 5 5 5 10 | 0, 5, 5, 5, 10 |
Try It
The total cost of textbooks for the term was collected from 36 students. Find the 5 number summary of this data. $140 $160 $160 $165 $180 $220 $235 $240 $250 $260 $280 $285 $285 $285 $290 $300 $300 $305 $310 $310 $315 $315 $320 $320 $330 $340 $345 $350 $355 $360 $360 $380 $395 $420 $460 $460Example
Returning to the household income data from earlier in the section, create the five-number summary.| Income (thousands of dollars) | Frequency |
| 15 | 6 |
| 20 | 8 |
| 25 | 11 |
| 30 | 17 |
| 35 | 19 |
| 40 | 20 |
| 45 | 12 |
| 50 | 7 |
Answer: By adding the frequencies, we can see there are 100 data values represented in the table. In Example 20, we found the median was $35 thousand. We can see in the table that the minimum income is $15 thousand, and the maximum is $50 thousand. To find Q1, we calculate the locator: L = 0.25(100) = 25. This is a whole number, so Q1 will be the mean of the 25th and 26th data values. Counting up in the data as we did before, There are 6 data values of $15, so Values 1 to 6 are $15 thousand The next 8 data values are $20, so Values 7 to (6+8)=14 are $20 thousand The next 11 data values are $25, so Values 15 to (14+11)=25 are $25 thousand The next 17 data values are $30, so Values 26 to (25+17)=42 are $30 thousand The 25th data value is $25 thousand, and the 26th data value is $30 thousand, so Q1 will be the mean of these: (25 + 30)/2 = $27.5 thousand. To find Q3, we calculate the locator: L = 0.75(100) = 75. This is a whole number, so Q3 will be the mean of the 75th and 76th data values. Continuing our counting from earlier, The next 19 data values are $35, so Values 43 to (42+19)=61 are $35 thousand The next 20 data values are $40, so Values 61 to (61+20)=81 are $40 thousand Both the 75th and 76th data values lie in this group, so Q3 will be $40 thousand. Putting these values together into a five-number summary, we get: 15, 27.5, 35, 40, 50
This example is demonstrated in this video. https://youtu.be/ECOeeDrUxpoBox plot
A box plot is a graphical representation of a five-number summary.examples
The box plot below is based on the 9 female height data with 5 number summary: 59, 62, 66, 69, 72.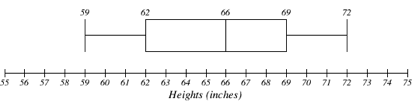
The box plot below is based on the household income data with 5 number summary: 15, 27.5, 35, 40, 50
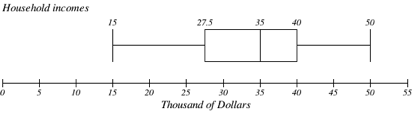 Box plot creation is described further here.
https://youtu.be/s4SPGFlMBMU
Box plot creation is described further here.
https://youtu.be/s4SPGFlMBMU
Try It
Create a box plot based on the textbook price data from the last Try It.examples
The box plot of service times for two fast-food restaurants is shown below.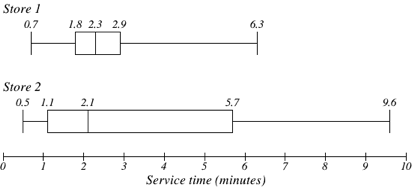 While store 2 had a slightly shorter median service time (2.1 minutes vs. 2.3 minutes), store 2 is less consistent, with a wider spread of the data.
At store 1, 75% of customers were served within 2.9 minutes, while at store 2, 75% of customers were served within 5.7 minutes.
Which store should you go to in a hurry?
While store 2 had a slightly shorter median service time (2.1 minutes vs. 2.3 minutes), store 2 is less consistent, with a wider spread of the data.
At store 1, 75% of customers were served within 2.9 minutes, while at store 2, 75% of customers were served within 5.7 minutes.
Which store should you go to in a hurry?
Answer: That depends upon your opinions about luck – 25% of customers at store 2 had to wait between 5.7 and 9.6 minutes.
The box plot below is based on the birth weights of infants with severe idiopathic respiratory distress syndrome (SIRDS)[footnote]van Vliet, P.K. and Gupta, J.M. (1973) Sodium bicarbonate in idiopathic respiratory distress syndrome. Arch. Disease in Childhood, 48, 249–255. As quoted on http://openlearn.open.ac.uk/mod/oucontent/view.php?id=398296§ion=1.1.3[/footnote]. The box plot is separated to show the birth weights of infants who survived and those that did not.
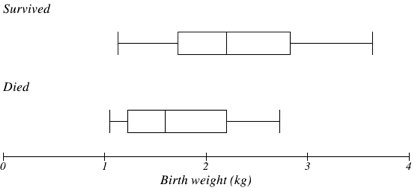 Comparing the two groups, the box plot reveals that the birth weights of the infants that died appear to be, overall, smaller than the weights of infants that survived. In fact, we can see that the median birth weight of infants that survived is the same as the third quartile of the infants that died.
Similarly, we can see that the first quartile of the survivors is larger than the median weight of those that died, meaning that over 75% of the survivors had a birth weight larger than the median birth weight of those that died.
Looking at the maximum value for those that died and the third quartile of the survivors, we can see that over 25% of the survivors had birth weights higher than the heaviest infant that died.
The box plot gives us a quick, albeit informal, way to determine that birth weight is quite likely linked to survival of infants with SIRDS.
The following video analyzes the examples above.
https://youtu.be/eUkgf-2NVO8
Comparing the two groups, the box plot reveals that the birth weights of the infants that died appear to be, overall, smaller than the weights of infants that survived. In fact, we can see that the median birth weight of infants that survived is the same as the third quartile of the infants that died.
Similarly, we can see that the first quartile of the survivors is larger than the median weight of those that died, meaning that over 75% of the survivors had a birth weight larger than the median birth weight of those that died.
Looking at the maximum value for those that died and the third quartile of the survivors, we can see that over 25% of the survivors had birth weights higher than the heaviest infant that died.
The box plot gives us a quick, albeit informal, way to determine that birth weight is quite likely linked to survival of infants with SIRDS.
The following video analyzes the examples above.
https://youtu.be/eUkgf-2NVO8
Licenses & Attributions
CC licensed content, Original
- Revision and Adaptation. Provided by: Lumen Learning License: CC BY: Attribution.
CC licensed content, Shared previously
- Measures of Variation. Authored by: David Lippman. Located at: http://www.opentextbookstore.com/mathinsociety/. License: CC BY-SA: Attribution-ShareAlike.
- Butte aux canons. Authored by: Alexandre Duret-Lutz. Located at: https://www.flickr.com/photos/gadl/299549598/. License: CC BY-SA: Attribution-ShareAlike.
- Finding range of a data set. Authored by: OCLPhase2's channel. License: CC BY: Attribution.
- Computing standard deviation 1. Authored by: OCLPhase2's channel. License: CC BY: Attribution.
- Five number summary 1. Authored by: OCLPhase2's channel. License: CC BY: Attribution.
- Five number summary 2. Authored by: OCLPhase2's channel. License: CC BY: Attribution.
- Five number summary 3. Authored by: OCLPhase2's channel. License: CC BY: Attribution.
- Five number summary from a frequency table. Authored by: OCLPhase2's channel. License: CC BY: Attribution.
- Creating a boxplot. Authored by: OCLPhase2's channel. License: CC BY: Attribution.
- Comparing boxplots. Authored by: OCLPhase2's channel. License: CC BY: Attribution.
